Deprecation Note
We published the last version of Graylog Documentation before the release of Graylog 4.2. Now, all documentation and help content for Graylog products are available at https://docs.graylog.org/.
There will be no further updates to these pages as of October 2021.
Do you have questions about our documentation? You may place comments or start discussions about documentation here: https://community.graylog.org/c/documentation-campfire/30
The thinking behind the Graylog architecture and why it matters to you¶
A short history of Graylog¶
The Graylog project was started by Lennart Koopmann some time around 2009. Back then the most prominent log management software vendor issued a quote for a one year license of their product that was so expensive that he decided to write a log management system himself. Now you might call this a bit over optimistic (I’ll build this in two weeks, end of quote) but the situation was hopeless: there was basically no other product on the market and especially no open source alternatives.
The log management market today¶
Things have changed a bit since 2009. Now there are viable open source projects with serious products and a growing list of SaaS offerings for log management.
Architectural considerations¶
Graylog has been successful in providing log management software because it was built for log management from the beginning. Software that stores and analyzes log data must have a very specific architecture to do it efficiently. It is more than just a database or a full text search engine because it has to deal with both text data and metrics data on a time axis. Searches are always bound to a time frame (relative or absolute) and only going back into the past because future log data has not been written yet. A general purpose database or full text search engine that could also store and index the private messages of your online platform for search will never be able to effectively manage your log data. Adding a specialized frontend on top of it makes it look like it could do the job in a good way but is basically just putting lipstick on the wrong stack.
A log management system has to be constructed of several services that take care of processing, indexing, and data access. The most important reason is that you need to scale parts of it horizontally with your changing use cases and usually the different parts of the system have different hardware requirements. All services must be tightly integrated to allow efficient management and configuration of the system as a whole. A data ingestion or forwarder tool is hard to tedious to manage if the configuration has to be stored on the client machines and is not possible via for example REST APIs controlled by a simple interface. A system administrator needs to be able to log into the web interface of a log management product and select log files of a remote host (that has a forwarder running) for ingestion into the tool.
You also want to be able to see the health and configuration of all forwarders, data processors and indexers in a central place because the whole log management stack can easily involve thousands of machines if you include the log emitting clients into this calculation. You need to be able to see which clients are forwarding log data and which are not to make sure that you are not missing any important data.
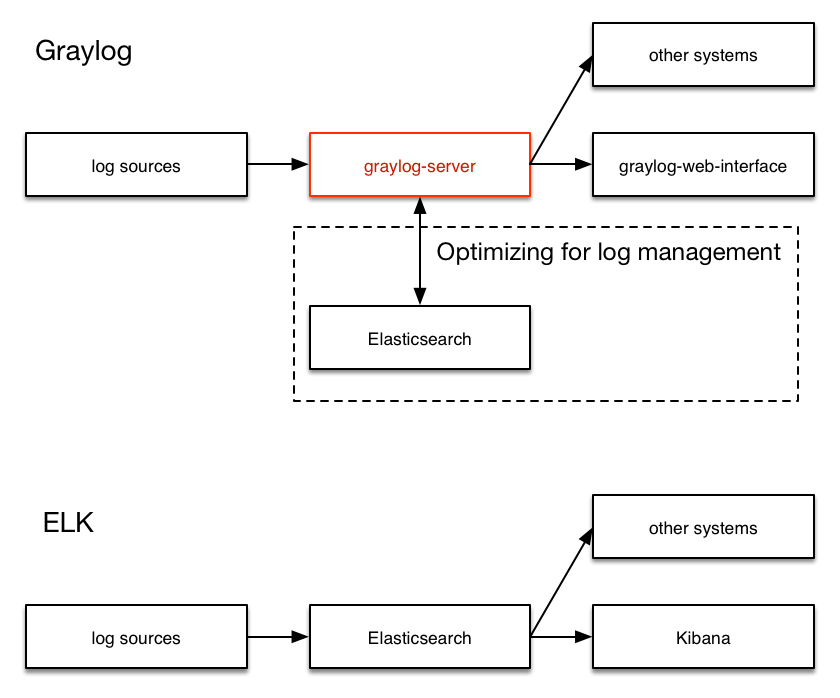
Graylog is coming the closest to the Splunk architecture:
Graylog was solely built as a log management system from the first line of code. This makes it very efficient and easy to use.
The
graylog-servercomponent sits in the middle and works around shortcomings of Elasticsearch (a full text search engine, not a log management system) for log management. It also builds an abstraction layer on top of it to make data access as easy as possible without having to select indices and write tedious time range selection filters, etc. - Just submit the search query and Graylog will take care of the rest for you.All parts of the system are tightly integrated and many parts speak to each other to make your job easier.
Like WordPress makes MySQL a good solution for blogging, Graylog makes Elasticsearch a good solution for logging. You should never have a system or frontend query Elasticsearch directly for log management so we are putting
graylog-serverin front of it.
Blackboxes¶
Closed source systems tend to become black boxes that you cannot extend or adapt to fit the needs of your use case. This is an important thing to consider especially for log management software. The use cases can range from simple syslog centralization to ultra flexible data bus requirements. A closed source system will always make you depending on the vendor because there is no way to adapt. As your setup reaches a certain point of flexibility you might hit a wall earlier than expected.
Consider spending a part of the money you would spend for the wrong license model for developing your own plugins or integrations.
The future¶
Graylog is the only open source log management system that will be able to deliver functionality and scaling in a way that Splunk does. It will be possible to replace Elasticsearch with something that is really suited for log data analysis without even changing the public facing APIs.